RAG, short for retrieval augmented generation is a technique used for prompting LLMs on some data provided by the user.
it is a technique used for enhancing the responses generated by the LLMs by generating responses with better accuracy and reliability.
Nvidia Blog on RAG
Retrieval-augmented generation (RAG) is a technique for enhancing the accuracy and reliability of generative AI models with facts fetched from external sources.
In other words, it fills a gap in how LLMs work. Under the hood, LLMs are neural networks, typically measured by how many parameters they contain. An LLM’s parameters essentially represent the general patterns of how humans use words to form sentences.
That deep understanding, sometimes called parameterized knowledge, makes LLMs useful in responding to general prompts at light speed. However, it does not serve users who want a deeper dive into a current or more specific topic.
RAG was introduced first in the paper Retrieval-Augmented Generation for Knowledge Intensive NLP-Tasks which is linked below :
it was introduced as a way to link the generative AI service to external resources, especially those rich in latest technical details.
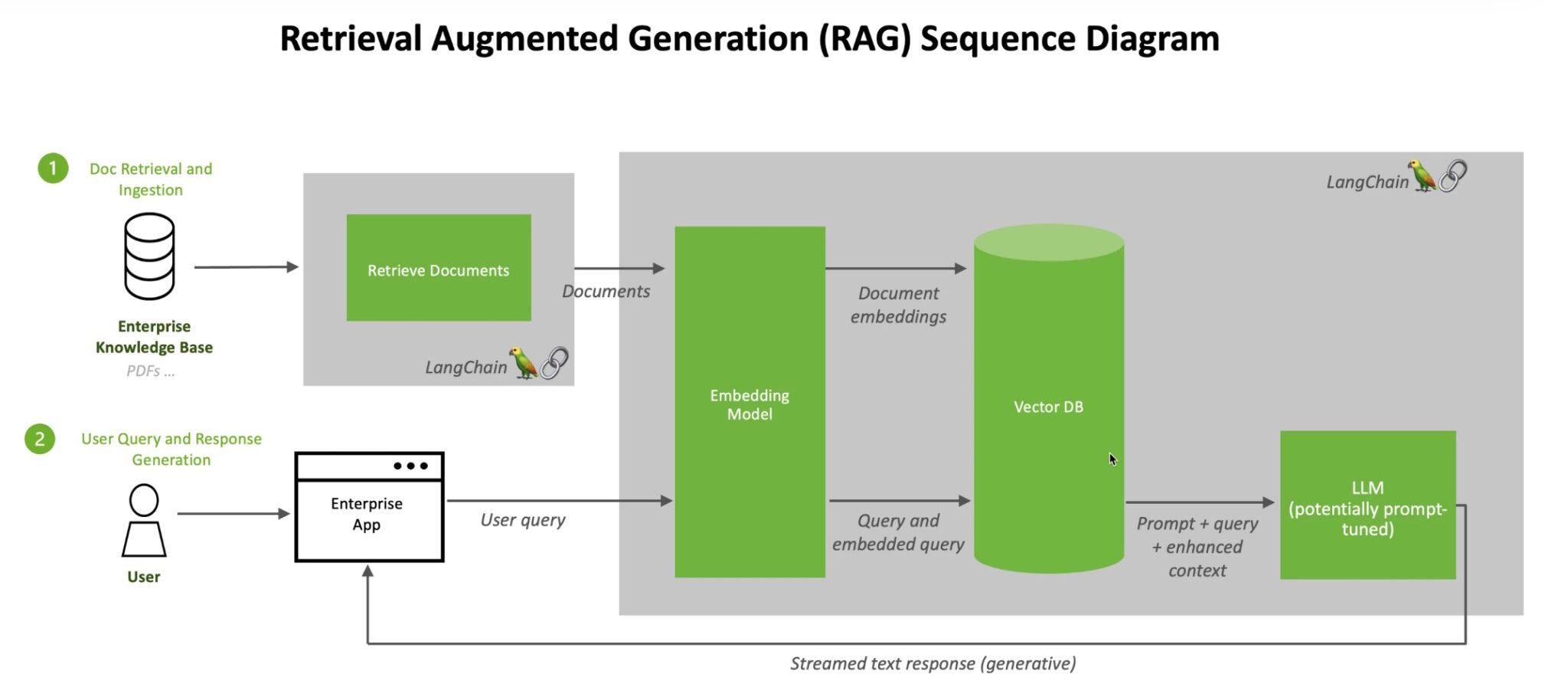
the RAG workflow works somewhat like this :
- a user sends in a query to an interface.
- the query then gets sent to the AI model that converts it into a numeric format which can be read by a machines.
- the query is in the form of an embedding/vector.
- the embedding model then compares these numerical values to the vectors in the machine-readable index of an available knowledge base.
- after it finds the match(es), it simply retrieves the data → converts it to human readable format and passes it back to the LLM.
image from the Nvidia Blog : https://blogs.nvidia.com/blog/what-is-retrieval-augmented-generation/